![]() Colaboradores de TRADERS'
Colaboradores de TRADERS'
TRADERS'
Este artículo ha sido escrito por Eduardo López Gonzalo y Miguel Ángel Rodríguez Crespo
En este artículo analizamos el uso de un modelo de Aprendizaje Máquina para mejorar los sistemas de rotura del rango inicial, también conocidos como sistemas ORB por su nombre en inglés Opening Range Breakout. Este modelo ya lo propusimos anteriormente en el número de Abril 2020 de esta revista. Después de explicar el modelo y describir las ventajas del mismo, ponemos como ejemplo el sistema resultante sobre el futuro del DAX, y a diferencia del artículo anterior discutimos el uso de diversos parámetros y su influencia en los resultados del sistema de trading, lo que nos permite extraer conclusiones para la operativa de un trader sobre este mercado.
Toby Crabel en su libro “Day Trading with Short Term Price Patterns and Opening Range Breakout” popularizó los sistemas de rotura del rango de apertura en los años ’90, que hoy en día se conocen como sistemas ORB. En realidad, ya Crabel introdujo algunas variaciones de este tipo de sistemas, pero en general se trata de establecer un rango de precios tal que el sistema compra cuando el precio cruza hacia arriba un límite superior o vende cuando el precio cruza hacia abajo un límite inferior. Estos límites superior e inferior pueden quedar definidos después de esperar unos minutos tras la apertura del mercado viendo el rango de precios que se ha dado y fijando los límites a una distancia de este rango inicial. Otro método, también propuesto por Crabel, es fijar el rango de precios a una distancia dada igual por arriba y por abajo del precio de apertura y operar si se produce una rotura de ese rango así establecido. Existen por tanto multitud de métodos para establecer este rango inicial. En este artículo consideramos otro método para ver si compramos o vendemos antes de que el precio cruce el rango delimitado en los primeros minutos después de la apertura y es por lo que lo denominamos “ORB predictivo” en contraposición al “ORB tradicional” descrito por Toby Crabel. Nuestro estudio nos lleva a considerar el uso de diversos parámetros que nos permitirá extraer conocimiento que puede usar un trader sobre el mercado DAX.
Uno de los problemas de un sistema ORB tradicional en el que esperamos la rotura de un rango establecido en los primeros minutos de mercado, es justamente la elección de la duración del periodo de tiempo que delimita el rango inicial. Así, cuanto más esperamos en delimitar el rango desde la apertura, mayor será el rango inicial en precio, por lo que, aunque sea mayor la probabilidad de que el precio siga esa tendencia establecida, lo cierto es que será menor el posible beneficio potencial.
La idea del ORB predictivo es predecir la tendencia grande del día, pero usando un rango de tiempo desde la apertura muy pequeño. En estas condiciones tendríamos todo el beneficio potencial ya que operamos pronto en el día sin esperar la rotura del rango y la tendencia que estamos aprovechando estaría en la dirección correcta. La idea es usar técnicas de Aprendizaje Máquina e Inteligencia Artificial para predecir, poco tiempo después de la apertura, si el día va a ser alcista o bajista. Estamos pues clasificando los días de trading en alcista o “bullish” y bajista o “bearish” usando un método supervisado que en nuestro caso va a ser la regresión logística. Al ser un método supervisado debemos tener datos de entrenamiento etiquetados como alcistas ó bajistas para entrenar el método de clasificación, para ello partimos de datos de apertura-máximo-mínimo-cierre con una granularidad de 1 minuto.
Obtención de las etiquetas de referencia
Para entrenar un modelo de aprendizaje automático es necesario disponer de las etiquetas verdaderas (reales o de referencia) de un amplio conjunto de días.
En el sistema inicial del que partió este trabajo descrito en el número de abril de 2020, las etiquetas de referencia se obtenían mediante el uso de unos umbrales que se determinaban a partir del valor de apertura del día, sumándole y restándole un valor llamado “bisagra”. Se veía cuál de los umbrales se alcanzaba antes a lo largo del día y, de acuerdo al umbral alcanzado, se determinaba la etiqueta BULLISH (o alcista) del día. Si el umbral alcanzado era el superior, la etiqueta era TRUE, y si era el inferior, la etiqueta era FALSE.
La bisagra para un día se definió como el mínimo valor absoluto de dos rangos: la diferencia entre el máximo del día y el valor de apertura, y la diferencia entre el valor de apertura y el mínimo del día. Para que este valor representara el rango “habitual” de los movimientos contrarios a la tendencia general de los días pasados, se hizo una media móvil de estos valores en los 20 días previos al día de interés. Este valor de la media podía ser incrementado hasta en dos veces la desviación típica, para ajustar el funcionamiento del etiquetado.
En el sistema actual se ha desarrollado un nuevo procedimiento para hacer el etiquetado. Dado que para asignar etiquetas a los días se cuenta con un histórico de días en el que se conocen todos los datos de la evolución del valor a lo largo de cada día completo, es preferible disponer de un etiquetado en el que la etiqueta del día no se vea influida por estimaciones de valores obtenidas de días previos, ni haya que realizar ajustes sobre esa estimación, ni establecer unos umbrales basados en ella. El nuevo procedimiento de etiquetado es más simple y se basa únicamente en el cálculo de un parámetro que sólo tiene en cuenta los datos de la evolución del valor en el propio día.
El parámetro usado para determinar las etiquetas de referencia es el que hemos denominado “desplazamiento” o “displ” (de “displacement”). Este parámetro representa el desequilibrio del rango de la evolución del valor a lo largo del día, respecto al valor de apertura del día. Para el cálculo de “displ”, nos servimos del máximo valor del día (el máximo de los “high” de cada minuto, al que podemos llamar “high”), y del mínimo valor del día (el mínimo de los “low” de cada minuto, al que podemos llamar “low”). El valor de apertura (el “open” del primer minuto del día) necesariamente ha de estar comprendido entre “high” y “low”. En los casos más extremos, el valor de apertura será igual a “high” si durante todo el intervalo el valor sólo se ha mantenido o ha bajado (nunca ha superado el valor “open” en todo el día), o será igual a “low” si sólo se ha mantenido o ha subido (nunca ha bajado del valor “open”). El desplazamiento puede representar de una manera simple la asimetría en la evolución del valor como la diferencia del punto medio entre “high” y “low” y el valor de apertura:
-
displ = ((high + low) / 2) – open
El desplazamiento podrá ser positivo (si “open” queda por debajo del punto medio) o negativo (si “open” queda por encima del punto medio). Un valor positivo de “displ” indicará que la etiqueta de referencia BULLISH del día es TRUE, e indicará que es FALSE si es negativo. En los casos en que “displ” sea exactamente 0, se recurrirá a los valores de apertura y cierre del día (si el valor de cierre es superior al de apertura BULLISH será TRUE, y en caso contrario será FALSE).
Se hicieron una serie de comparaciones entre el nuevo etiquetado y el anterior basado en umbrales, variando los ajustes de este último. La coincidencia entre las etiquetas estuvo entre el 88% y el 95%. En los casos en que las etiquetas eran distintas se hizo una revisión manual comprobando las curvas de la evolución temporal del valor en esos días. En algunos de estos casos había un movimiento inicial significativo (que rompía alguno de los umbrales del sistema anterior) que luego no resultaba ser el mayor del día. Normalmente este movimiento inicial se producía rápidamente al principio del día. Los umbrales deberían haber tenido un rango algo superior para haber detectado correctamente el mayor movimiento del día. En otros casos, no se producía ningún cruce del precio con los umbrales. Generalmente, la apertura dividía el rango en dos mitades muy similares (gran indecisión en la tendencia del día). Vistos los resultados, decidimos aceptar el nuevo mecanismo como una mejor alternativa para obtener las etiquetas de referencia.
Conjunto de predictores
El entrenamiento de un modelo de aprendizaje automático supervisado necesita, además de las etiquetas BULLISH de referencia de cada día (variable objetivo), un conjunto de variables predictoras (vector de características) que son las que nos permitirán calcular, tras el entrenamiento del modelo, el valor predicho de la variable objetivo para un vector de características dado.
El vector de características incorporará variables correspondientes a cada uno de los días previos (actualmente, 4 días previos) por separado, también variables que son un agregado de distintas variables de los días previos (como su media o su varianza) y variables correspondientes al intervalo tomado como inicio del día actual.
Por ejemplo, tomemos el caso de una variable concreta de un día, como “close_open”. Ésta se calcula por separado para cada día como el valor de cierre menos el valor de apertura.
En el vector de características se incorporarán las variables correspondientes a cada uno de los días anteriores: p4_close_open, p3_close_open, p2_close_open, p1_close_open. Los prefijos p4, p3, p2 y p1 se refieren respectivamente a “hace 4 días”, “hace 3 días”, “hace 2 días” y “hace un día” (el día inmediatamente anterior al actual). También se incorporan la media y desviación típica de esos 4 valores en los días previos: p_close_open_mean y p_close_open_sd.
El inicio del día actual se considera como un día truncado, limitado a un número menor de instantes de tiempo. Si el intervalo de inicio es de 1 minuto (valor tomado actualmente), se obtiene una nueva variable (ini_close_open) que sería el valor de cierre al final del día truncado (valor de cierre del minuto 1) menos el valor de apertura al inicio del día truncado (valor de apertura del primer minuto, que en este caso también es el minuto 1).
Por tanto, a partir de esta única variable (close_open) que se puede calcular para los distintos días previos y para el inicio del día, llegamos a introducir en el vector de características 7 variables diferentes que se usarán como predictores para el día actual. Y, evidentemente, esto se hace para muchas más variables de este tipo.
Algunas de las variables serán numéricas, como el ejemplo de “close_open” visto anteriormente. Otras variables serán etiquetas de los días anteriores o del inicio del día actual. Estas variables se dice que son de tipo “factor” (frente a las variables numéricas), y pueden tener sólo ciertos valores distintos (llamados habitualmente “niveles”). Por ejemplo, podemos considerar la etiqueta BULLISH. Esta variable de tipo “factor” sólo valdrá TRUE o FALSE. De esta variable podemos considerar los siguientes predictores para el vector de características: p4_is_bullish, p3_is_bullish, p2_is_bullish, p1_is_bullish, ini_is_bullish. Y a partir de ellas podemos añadir una nueva variable de tipo factor al vector de características: seq_is_bullish, que es la secuencia de valores de los 4 días anteriores y el inicio del día actual. Esta variable también es de tipo “factor”, pero tendrá un conjunto de 25 = 32 posibles valores (las distintos grupos de 5 elementos con dos valores posibles cada uno: TRUE-TRUE-TRUE-TRUE-TRUE, TRUE-TRUE-TRUE-TRUE-FALSE, … , FALSE-FALSE-FALSE-FALSE-FALSE).
El vector de características se compone actualmente de 143 predictores, 128 de los cuales son de tipo numérico y 15 son de tipo factor.
Definición y uso del parámetro “hinge” (“bisagra”). Estrategia de trading
Como se ha comentado en el apartado de la obtención de las etiquetas de referencia, en el sistema actual no se usa la “bisagra” para ese fin. Pero sí se usa un parámetro similar, al que hemos llamado “hinge”, con una doble finalidad:
- Como uno de los parámetros de un día, a partir del cual se obtienen algunos de los componentes del vector de características de cada día (p4_hinge, p3_hinge, p2_hinge, p1_hinge, p_hinge_mean, p_hinge_sd, ini_hinge). Es decir, para generar algunos de los predictores del modelo que se usarán primero para entrenar dicho modelo y para obtener después la etiqueta “BULLISH” predicha para un día, conociendo sólo valores de los días anteriores y del inicio de día actual, incluidos en el vector de características.
- Para establecer, a partir del valor de apertura del día y de p_hinge_mean, los umbrales que se usarán en la estrategia de trading, según vamos a explicar más adelante.
Este parámetro “hinge” lo hemos definido como la mitad del rango máximo de un día. Es decir, como: (high – low) / 2. Si este parámetro se usara para establecer unos umbrales simétricos alrededor del valor de apertura del día, y si esos umbrales se usaran para obtener la etiqueta de ese mismo día mediante la estrategia de rotura de umbrales (al estilo de cómo se hacía en el sistema anterior), se obtendrían exactamente las mismas etiquetas de referencia que con el nuevo sistema empleado basado en el signo del parámetro “displ”.
En la estrategia de trading que seguimos en el sistema actual, una vez transcurrido el intervalo de ”inicio del día”, si la etiqueta BULLISH predicha por el modelo es TRUE, se hace una operación de compra. En caso contrario, se hace una operación de venta. El valor “inicial” de la operación es el valor de apertura del primer minuto tras el intervalo de inicio del día actual.
También se establecen unos umbrales superior e inferior, a partir del valor de apertura del día actual. Evidentemente, no se dispone de los datos completos del día actual en el que va a operar el sistema. Sólo conocemos los datos del pasado (días anteriores, y lo que hemos establecido como “inicio del día”). Por tanto, no nos es posible establecer esos umbrales usando el “hinge” del día actual, que es desconocido. Los umbrales se establecerán tomando “p_hinge_mean” (la media del “hinge” de los 4 días anteriores) como un valor estimado del “hinge” del día actual. El emplear pocos días anteriores para hacer la estimación permite adaptarse mejor a las variaciones del “hinge” a lo largo del tiempo.
Estos umbrales establecen el “take profit” y “stop loss” de la operación de compra o venta inicial basada en la predicción de la etiqueta “BULLISH” del día actual, hecha por el modelo.
A medida que se van conociendo los nuevos valores de cada minuto a lo largo del día, se irá comprobando si el valor “rompe” alguno de los umbrales (el valor es mayor o igual que el umbral superior, o menor o igual que el umbral inferior). Cuando se alcance alguno de los umbrales, se deshará la operación. El valor “final” de la operación será el correspondiente al umbral alcanzado, o bien el valor de cierre del día, si no llega a alcanzarse ninguno de los dos umbrales.
El beneficio obtenido para este día será el valor “final” menos el valor “inicial” si la etiqueta BULLISH predicha fue TRUE, o el valor “inicial” menos el valor “final” si fue FALSE. Del beneficio se descuentan las comisiones y gastos de la operación (en nuestro caso, se han tomado iguales a 0.75 puntos).
El comportamiento deseado es que cuando la etiqueta BULLISH predicha sea TRUE, se alcance antes el umbral superior, y que cuando sea FALSE, se alcance antes el umbral inferior. Dependiendo de si la etiqueta BULLISH predicha para el día fue correcta o no (igual a la verdadera del día, que no se conoce de antemano) y de si los umbrales están bien estimados y funcionaron correctamente o no, el beneficio será positivo o negativo (pérdida).
Modelo predictivo de la etiqueta “BULLISH”
El tipo de modelo que se ha usado hasta ahora es una regresión logística. Este modelo se entrena, como hemos dicho, sobre un amplio conjunto de datos históricos de los que se conocen los valores de un repertorio de variables predictoras (vector de características) y también el valor verdadero de la variable que se quiere predecir (variable objetivo).
La variable objetivo es una variable binaria (sólo puede tomar dos valores). En nuestro caso, esos valores son TRUE o FALSE. Para hacer el entrenamiento, la variable objetivo queda representada por una variable numérica que recibe el valor 1 en los casos TRUE, y que recibe el valor 0 en los casos FALSE.
El entrenamiento consiste en ajustar un conjunto de coeficientes que, aplicados a los valores de las variables predictoras, permiten el mejor ajuste posible entre los valores de referencia de la variable objetivo y los valores predichos correspondientes (guiado por un criterio de reducción del error entre ambos conjuntos de valores).
Los valores predichos por el modelo de regresión logística son una variable numérica continua cuyos valores estarán comprendidos entre 0 y 1 (“score” o puntuación). Cuanto más próximo esté el “score” a 0, más probable será que la etiqueta predicha sea FALSE, y cuanto más próximo esté a 1, más probable será que la etiqueta predicha sea TRUE.
Sobre estos valores de “score” es necesario establecer un umbral que separe los casos en que la etiqueta predicha será TRUE (las que superen el umbral) y los casos en que será FALSE (las que no superen el umbral). Si los datos de entrenamiento tienen aproximadamente un número de casos parecido de etiquetas de referencia TRUE y FALSE, ese umbral se encontrará próximo al valor 0.5.
Si se quiere tener más seguridad de que la etiqueta predicha es “fiable”, se puede establecer un margen alrededor del umbral óptimo de los “score”, a costa de no arriesgarse a predecir en todos los casos. Por ejemplo, supongamos que establecemos para los scores un umbral mínimo “min_threshold” y un umbral máximo “max_threshold”, que estarán respectivamente por debajo y por encima de umbral considerado óptimo. Cuando el “score” no alcance “min_threshold”, se considerará que la predicción es fiable y es FALSE; cuando supere “min_threshold” pero no supere “max_threshold”, se considerará que la predicción no es fiable; cuando esté por encima de “max_threshold”, se considerará que la predicción es fiable y es TRUE.
En nuestro sistema actual, se ha usado esta idea. Se puede obtener una predicción para todos los días, o sólo en aquellos días en los que se considere que es fiable. Cuando la predicción no es fiable, se prefiere no operar (no comprar ni vender y, por tanto, obtener un beneficio 0). En nuestro caso, los umbrales “min_threshold” y “max_threshold” del “score” se han establecido de manera que, en promedio, no se opere el 50% de los días.
El conjunto total de datos con los que hemos trabajado son los días de cotización del DAX que van desde el inicio del año 1997 hasta el final de abril de 2021. Hemos tomado el 90% de los días como datos de entrenamiento (desde el inicio de 1997 hasta el 02-11-2018, con 5475 días de mercado), y el 10% restante como datos de test (desde el 05-11-2018 hasta el 30-04-2021, con 615 días de mercado).
Evitar el sobreentrenamiento
Si un modelo suficientemente complejo (con muchas variables predictoras) se entrena sobre un conjunto de datos no suficientemente grande (en comparación a la complejidad del modelo), se puede obtener un modelo que predice perfectamente (o casi) esos datos. Ese modelo puede ser muy bueno para predecir el pasado (es capaz de “recordarlo” muy bien) pero casi con total seguridad no será capaz de generalizar esos resultados para nuevos datos que no sean los de entrenamiento (que es lo que nos interesa: predecir el futuro). Es el conocido peligro del sobreentrenamiento.
Para eso hemos recogido un conjunto de datos de entrenamiento tan grande como nos ha sido posible. Y hemos reservado un conjunto de test (no usado en el entrenamiento) para comparar la corrección de las predicciones del modelo respecto a los valores de referencia en ambos conjuntos de datos por separado, y asegurarnos que no se produce sobreentrenamiento.
Otra protección contra el sobreentrenamiento consiste en hacer una buena selección de variables (simplificar el modelo). No todas las variables del vector de características se usarán como predictores del modelo.
Por una parte, se han construido modelos de una sola variable para todas las variables disponibles, y se han analizado las prestaciones de cada uno de los modelos para evaluar la capacidad predictiva de cada variable por separado. Si se juzga que una determinada variable no tiene una mínima capacidad predictiva para la variable objetivo, esa variable queda descartada.
Con las variables que superan el filtrado de capacidad predictiva individual se hace un estudio de correlación lineal entre ellas. El modelo subyacente de una regresión logística es un modelo de predicción lineal, y el ajuste de este tipo de modelos es sensible cuando existe una fuerte correlación lineal entre variables predictivas, pudiendo resultar un modelo final inestable. Por ello, con el estudio de correlación lineal entre las variables predictivas se descartan aquellas variables que estén demasiado correlacionadas con otras que, individualmente, tengan una mejor capacidad predictiva.
Tras la selección de variables, con los datos empleados, de los 143 predictores disponibles del vector de características, nos quedamos finalmente con 12 variables predictivas para entrenar el modelo.
Variables relevantes
En el entrenamiento del modelo se incluyó un procedimiento iterativo para ir incorporando variables al modelo, valorando cuál de las nuevas variables que se pueden añadir mejora en mayor medida el modelo existente antes de ser incluida dicha variable en el modelo.
Resulta curioso observar que las variables que se añaden en primer lugar son variables que corresponden a la caracterización del inicio del día, a pesar de que en el sistema actual ese periodo es sólo de 1 minuto.
Como ilustración, las dos primeras variables que se escogen en el procedimiento iterativo son las siguientes:
-
ini_close_rel: valor final del periodo de “inicio del día”, relativo a (dividido por) el valor de apertura del día.
- ini_low_open: diferencia entre el valor más bajo en el periodo de “inicio del día” y el valor de apertura del día.
Ejemplo de funcionamiento del sistema (backtest)
En este apartado presentamos un ejemplo de funcionamiento del sistema, aplicándolo a los datos de entrenamiento y test de la cotización del DAX presentados anteriormente.
En el proceso de entrenamiento del modelo, se obtuvo un valor de AUC (área bajo la curva ROC) de 0.566. El AUC es un parámetro usado habitualmente para medir la bondad del ajuste de un modelo de aprendizaje automático respecto a unos datos de referencia. El valor del AUC se encuentra entre 0.5 (modelo prácticamente aleatorio, sin capacidad predictiva) y 1 (modelo perfecto, que predice sin error los datos de referencia). El resultado, por tanto, nos dice que nuestro modelo tiene una capacidad predictiva bastante modesta.
Usando los datos de entrenamiento, se determinó el umbral óptimo empleado sobre los “scores” del modelo para establecer la frontera entre “BULLISH” TRUE y FALSE. Ese umbral resultó igual a 0.522. También se establecieron los umbrales “min_threshold” (0.4605) y “max_threshold” (0.5326) del “score” de manera que el 50% de los datos de entrenamiento quedasen entre esos valores. Los “scores” fuera de ese intervalo son los que corresponden a predicciones “fiables”.
Una vez entrenado el modelo, se aplicó sobre los datos de test. El valor del AUC para estos datos resultó igual 0.559. Es un valor muy similar al obtenido para los datos de entrenamiento, lo que nos indica que no existe sobreentrenamiento.
La prueba de “backtest” se completó obteniendo el beneficio (o pérdida) que se hubiera obtenido cada uno de los días del periodo de test (entre el 05-11-2018 y el 30-04-2021), siguiendo el procedimiento que hemos descrito en este artículo. Esto se hizo tanto considerando todas las etiquetas BULLISH como “fiables” (operando todos los días), como sólo operando cuando la etiqueta predicha es considerada “fiable” (“trusted”). Con los beneficios de cada día se obtuvo la evolución del beneficio acumulado a lo largo del periodo de test.
En primer lugar, presentamos en la Tabla 1 algunos resultados numéricos de esta prueba. Entre esos resultados se encuentra el máximo “drawdown”, que es la máxima pérdida que podría producirse dentro del periodo de análisis. También se encuentra el “Return over Maximum Drawdown” (RoMaD). Este parámetro representa el cociente entre el beneficio acumulado al final del periodo y el máximo “drawdown” dentro de dicho periodo.
En los resultados se puede ver cómo, en general, el operar únicamente en días “fiables” frente a operar todos los días mejora los resultados. Por ejemplo, el beneficio medio de las operaciones realizadas pasa de 1.12 a 9.42. También el máximo “drawdown” se reduce de 2439.5 a 1602.2. Si nos fijamos en el RoMaD, si durante los días de test se hubiera operado los días “fiables” de acuerdo al sistema propuesto, el valor obtenido hubiera sido de 1.97; es decir, el beneficio acumulado al final del periodo hubiera sido prácticamente el doble del máximo riesgo de pérdida.
También presentamos una gráfica (Figura 1) que ilustra la evolución del beneficio acumulado dentro del periodo de test. En la gráfica aparecen dos curvas. La curva azul representa el caso de haber operado todos los días. La curva roja representa el caso de haber operado sólo los días con etiqueta BULLISH “fiable”. En la figura también aparecen marcados los instantes de tiempo y los valores que determinan el máximo “drawdown” en cada caso (con líneas punteadas). La curva azul presenta un resultado final sólo ligeramente superior al inicial del periodo (pequeño beneficio neto total). La curva roja, aparte de tener un beneficio neto final claramente superior, muestra una tendencia ascendente bastante sostenida a lo largo del tiempo, y las diferentes bajadas (posibles pérdidas) son más suaves y moderadas. Hay que tener en cuenta, además, que la prueba se ha hecho en un intervalo temporal de gran volatilidad en los mercados debido a la pandemia por el SARS-CoV-2.
Conclusiones y posibles evoluciones del sistema
El sistema que hemos presentado no puede considerarse todavía como un trabajo acabado. Por una parte, sería conveniente explorar algunas opciones más de diversos parámetros que se han aplicado (como el número de minutos de “inicio del día”, el número de días previos…).
Sería muy útil disponer de un modelo que obtuviera mejores resultados en la tarea de clasificación de la etiqueta “BULLISH” de cada día. En general, un modelo con una tasa de acierto al predecir datos nuevos de aproximadamente el 53% o el 57% (la que tenemos actualmente cuando trabajamos con todos los días, o con los días “fiables”) está lejos de ser un buen modelo, aunque haya aplicaciones en las que su uso resulte útil (como puede ser nuestro caso).
Para ilustrar el beneficio que se podría obtener en el sistema mejorando la predicción del tipo de día, hemos hecho algunas simulaciones. Por ejemplo, hemos generado los resultados del “backtest” que se obtendrían si tuviéramos un modelo capaz de acertar correctamente el 60% de las etiquetas predichas, escogidas aleatoriamente entre los datos de test, y todas esas etiquetas fueran “fiables”. Esto lo podemos hacer porque ya conocemos las etiquetas de referencia del periodo de test, así que “forzamos” que en un 60% de los casos coincidan con las etiquetas predichas por ese supuesto modelo, y no coincidan en el 40% restante de los casos.
En la Figura 2 presentamos los resultados de una simulación en estas condiciones. Si se hacen varias ejecuciones de esta simulación cada vez se obtienen unas curvas diferentes en los detalles, pero con un comportamiento general similar. Obsérvese que, además de tener una evolución claramente creciente, con menos oscilaciones y, en general, más suaves, el rango del beneficio total acumulado (eje Y) es superior al del sistema actual.
En el futuro este será nuestro objetivo, alcanzar una tasa de acierto cercana al 60%. Los caminos para llegar a mejorar la clasificación de las etiquetas son de distinto tipo. Por una parte, ajustar parámetros (como hemos dicho antes), por otra incorporar nuevos predictores al modelo que sean capaces de reflejar informaciones que no recogen los predictores actuales. Y también se podrían aplicar nuevas técnicas de aprendizaje automático (otro tipo de modelos) capaces de mejorar algo más la tasa de acierto.
Tablas y figuras
TABLA 1: Algunas métricas del resultado de la prueba de “backtest” sobre los datos de test.
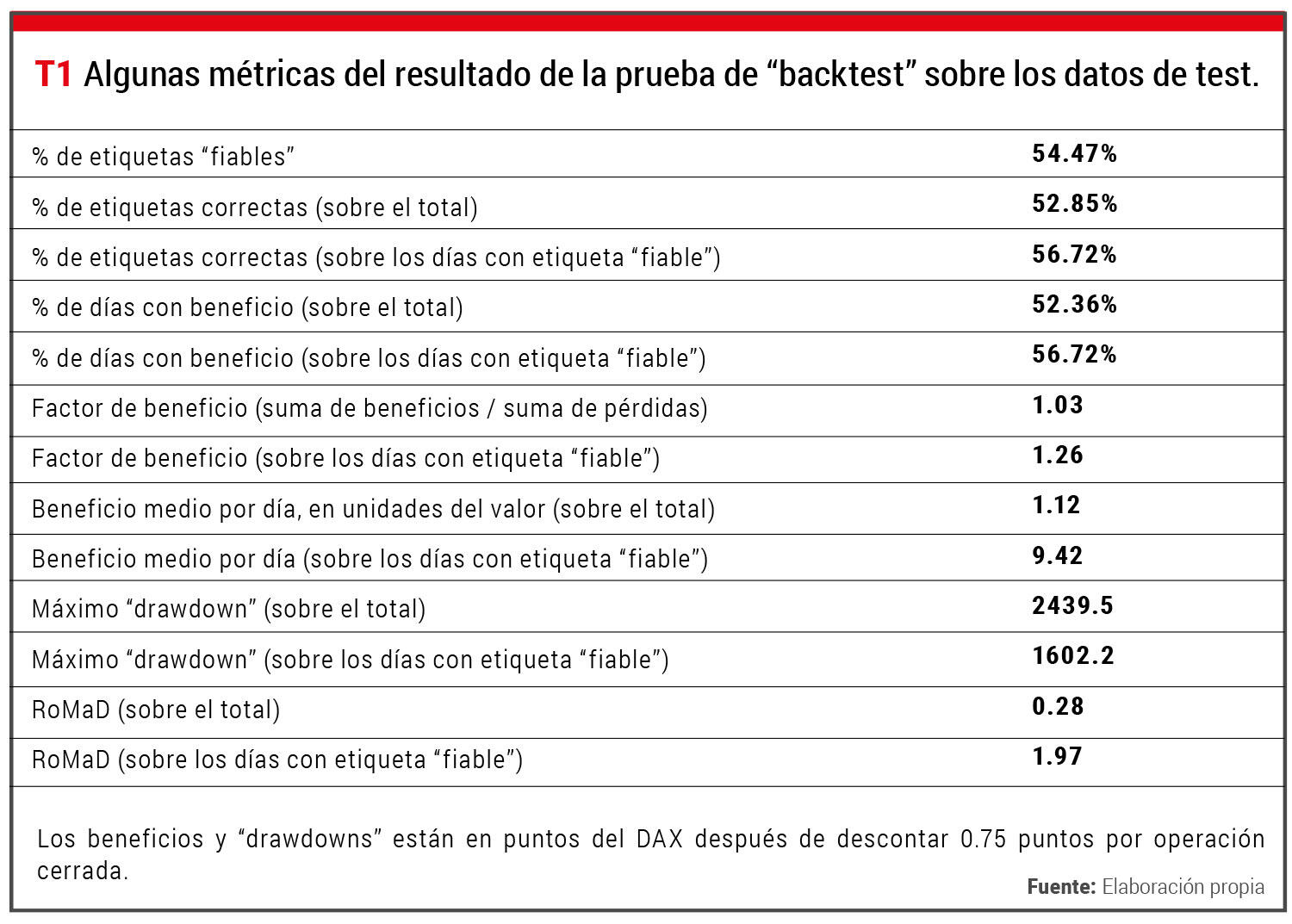
Los beneficios y “drawdowns” están en puntos del DAX después de descontar 0.75 puntos por operación cerrada. Fuente: Elaboración propia
Figura 1: Backtest sobre los datos de test. Sistema actual
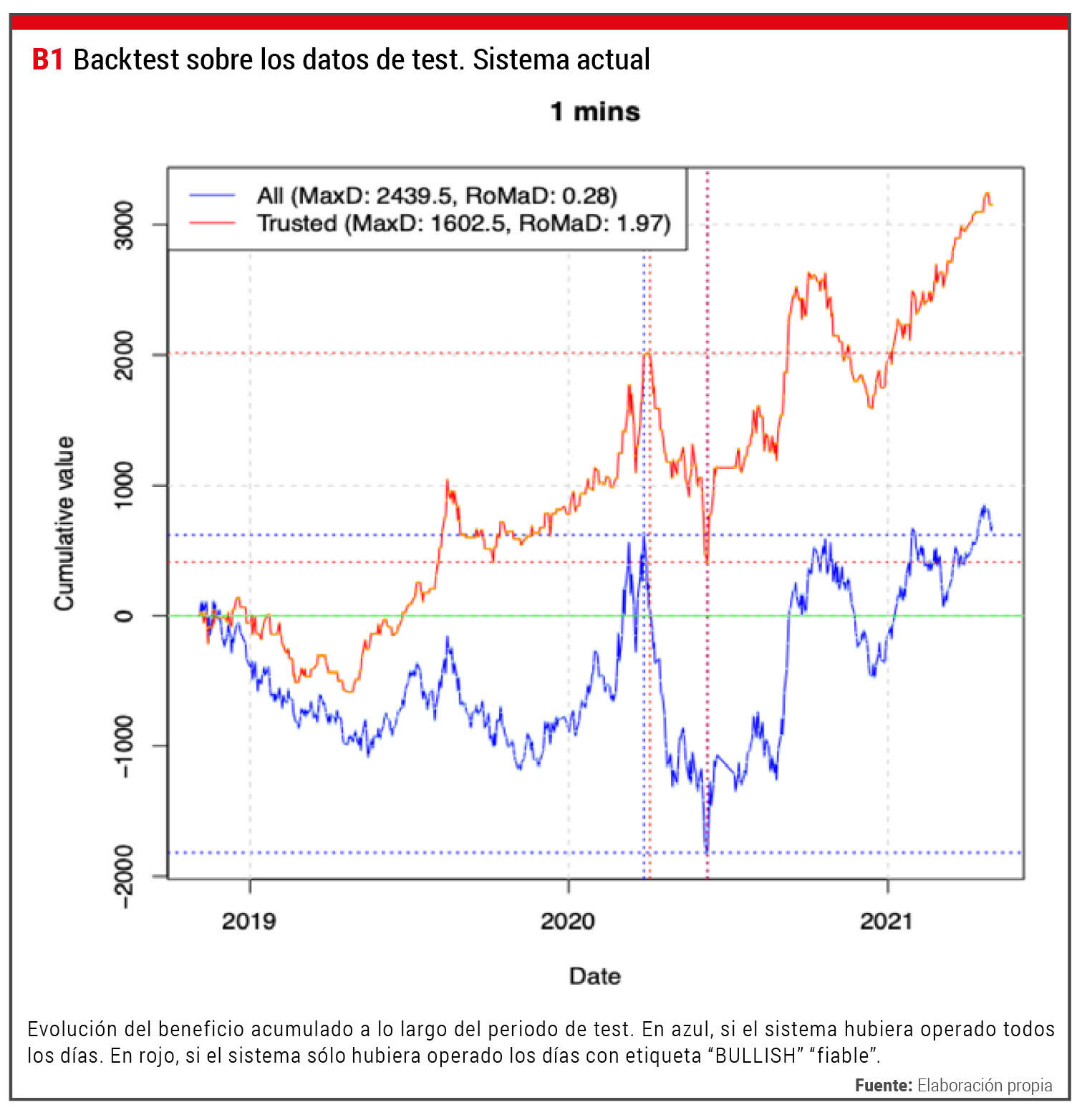
Evolución del beneficio acumulado a lo largo del periodo de test. En azul, si el sistema hubiera operado todos los días. En rojo, si el sistema sólo hubiera operado los días con etiqueta “BULLISH” “fiable”. Fuente: Elaboración propia
Figura 2: Backtest sobre los datos de test. Simulación 60%
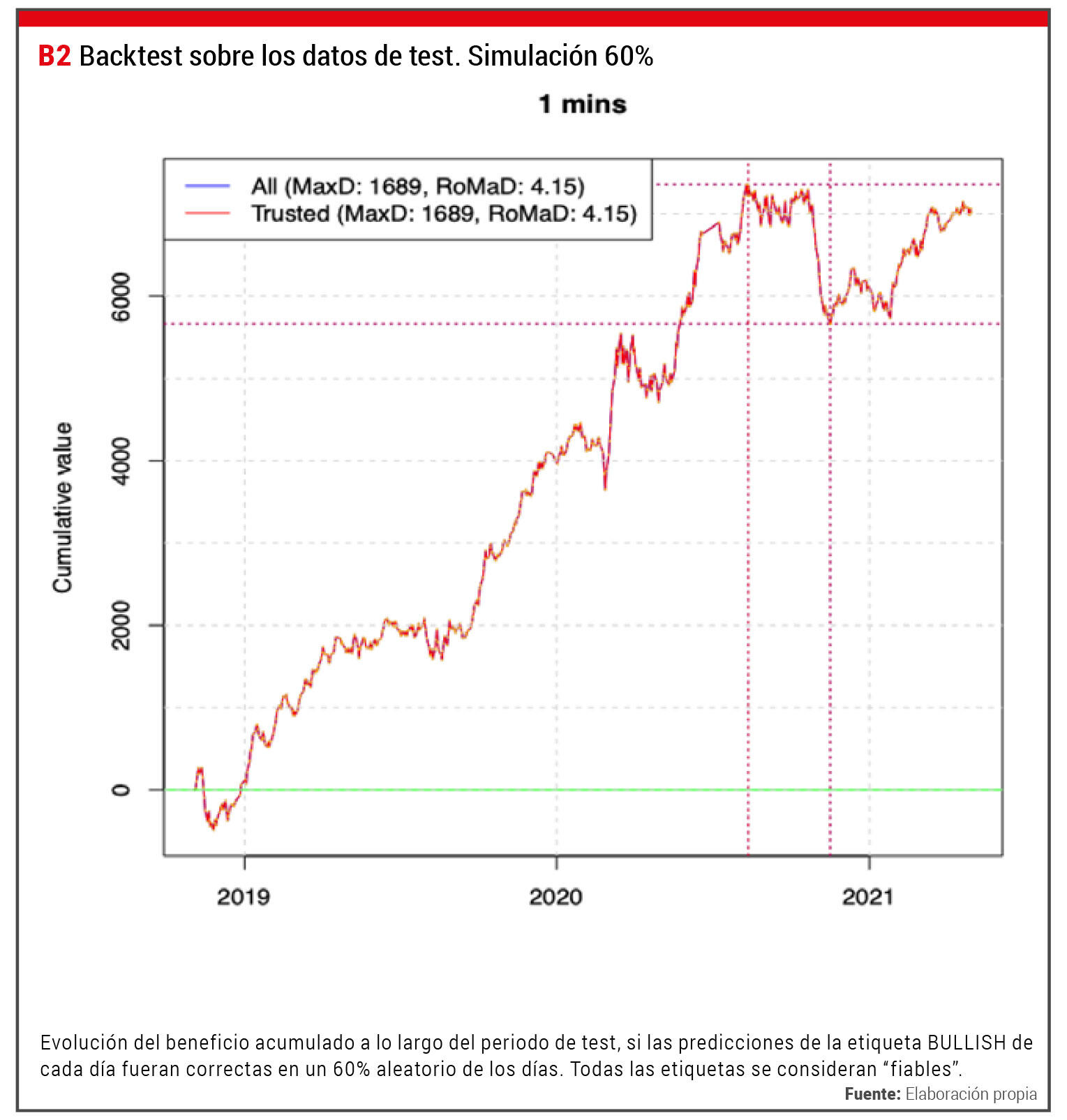
Evolución del beneficio acumulado a lo largo del periodo de test, si las predicciones de la etiqueta BULLISH de cada día fueran correctas en un 60% aleatorio de los días. Todas las etiquetas se consideran “fiables”. Fuente: Elaboración propia
Toda información publicada en TRADERS’ es únicamente para fines educativos. No pretende recomendar, promocionar o de cualquier manera sugerir la eficacia de cualquier sistema, estrategia o enfoque de trading. Se recomienda a los traders que realicen sus propias investigaciones, desarrollo y comprobaciones para determinar la validez de un concepto para el trading. El trading y la inversión conllevan un alto nivel de riesgo. Cualquier persona con la intención de operar en los mercados financieros debe entender y aceptar estos riesgos. El rendimiento obtenido en el pasado no es garantía de los resultados futuros.
Contenido Recomendado

EUR/USD Pronóstico Semanal: Es improbable que la decisión del BCE rescate al Euro
El par EUR/USD ha mostrado pocos avances en los últimos días, oscilando en torno a la marca de 1.1450 durante toda la semana para cerrar unos pocos pips por debajo del nivel. Las crecientes tensiones en Oriente Medio llevaron a los inversores a un modo cauteloso a pesar del alivio temporal por los datos macroeconómicos.

La Libra esterlina se debilita mientras el Dólar avanza ante el aumento de la aversión al riesgo
El GBP/USD amplía sus pérdidas por segundo día consecutivo, cotizando en torno a 1.3460 durante la sesión asiática del viernes. El par de divisas tiene un peor desempeño, ya que el Dólar estadounidense (USD) obtiene apoyo como activo refugio por la intensificación de los conflictos geopolíticos en Oriente Medio, justo antes del Índice preliminar de Sentimiento del Consumidor de Michigan de julio.

El Yen japonés lucha mientras una amplia brecha de tasas entre EE.UU. y Japón pesan
El USD/JPY cotiza plano el viernes, manteniéndose cerca de máximos de cuatro décadas mientras el Yen japonés lucha por atraer compradores en medio de vientos en contra persistentes, incluidos los precios más altos del petróleo, el amplio diferencial de tipos de interés de Japón con otras grandes economías y un Dólar estadounidense (USD) resiliente.
Contenido recomendado

El IPC se enfría, pero la inflación no ha desaparecido: Qué hay detrás de los titulares
El último informe del Índice de Precios al Consumo de junio generó optimismo en los mercados financieros, pero ¿qué hay detrás?

El Peso mexicano cae a mínimos de ocho días frente a un Dólar respaldado por la subida de los precios del petróleo
El USD/MXN registra su segunda jornada consecutiva de ganancias este viernes, elevándose desde un mínimo diario en 17.41 a un máximo no visto desde el 9 de julio en 17.55. A media sesión americana, el par cotiza sobre 17.53, ganando un 0.65% en el día.

La posible recuperación del Bitcoin en la segunda mitad de 2026 depende de estos 4 catalizadores
El Bitcoin (BTC) ha caído más de un 34% en la primera mitad de este año, ya que el Rey Cripto no logró capitalizar un buen semestre para los activos de riesgo pese a los problemas derivados de la guerra en Irán.
EUR/USD Pronóstico Semanal: Es improbable que la decisión del BCE rescate al Euro
El par EUR/USD ha mostrado pocos avances en los últimos días, oscilando en torno a la marca de 1.1450 durante toda la semana para cerrar unos pocos pips por debajo del nivel. Las crecientes tensiones en Oriente Medio llevaron a los inversores a un modo cauteloso a pesar del alivio temporal por los datos macroeconómicos.
Contenido recomendado
La importancia de las cuentas demo
Al empezar en este mundo de trading muy seguramente se observarán las palabras “cuenta demo”.
Quiero operar en una cuenta real, ¿cuál debe ser mi objetivo?
Es una pregunta que siempre realizo a todos mis alumnos, aquellos que, viéndose lo suficientemente preparados...
Estrategia de venta de opciones de compra cubierta mediante certificados de descuento
La venta de opciones de compra cubierta presupone que usted ya tiene el subyacente en su propia cartera o que lo comprará al mismo tiempo que se venden las opciones.
Operar las nóminas no agrícolas NFP de EE.UU.: Los 7 consejos principales que todo inversor de divisas debe conocer
Las cifras de empleo son vigiladas de cerca por el público en general, por los políticos y por los bancos centrales que mueven las divisas. EE.UU. es la economía más grande del mundo y su informe de empleos tiene más impacto que las cifras del mercado laboral de otros países.
Coaching Autogestión Emocional: Mi estilo atributivo
El modo en que explicamos nuestras pérdidas (fracasos) y nuestras ganancias (éxitos) y a los factores a los que atribuimos su causa, lo llamamos “estilo atributivo”. Existen cuatro estilos atributivos diferentes